Ponències/Comunicacions de congressos: Enviaments recents
Ara es mostren els items 13-24 de 187
-
XFeatur: Hardware feature extraction for DNN auto-tuning

(Institute of Electrical and Electronics Engineers (IEEE), 2022)
(Institute of Electrical and Electronics Engineers (IEEE), 2022)
Text en actes de congrés
Accés obertIn this work, we extend the auto-tuning process of the state-of-the-art TVM framework with XFeatur; a tool that extracts new meaningful hardware-related features that improve the quality of the representation of the search ... -
MEGsim: A Novel methodology for efficient simulation of graphics workloads in GPUs
(Institute of Electrical and Electronics Engineers (IEEE), 2022)
Text en actes de congrés
Accés obertAn important drawback of cycle-accurate microarchitectural simulators is that they are several orders of magnitude slower than the system they model. This becomes an important issue when simulations have to be repeated ... -
DTM-NUCA: dynamic texture mapping-NUCA for energy-efficient graphics rendering
(Institute of Electrical and Electronics Engineers (IEEE), 2022)
Text en actes de congrés
Accés obertModern mobile GPUs integrate an increasing number of shader cores to speedup the execution of graphics workloads. Each core integrates a private Texture Cache to apply texturing effects on objects, which is backed-up by a ... -
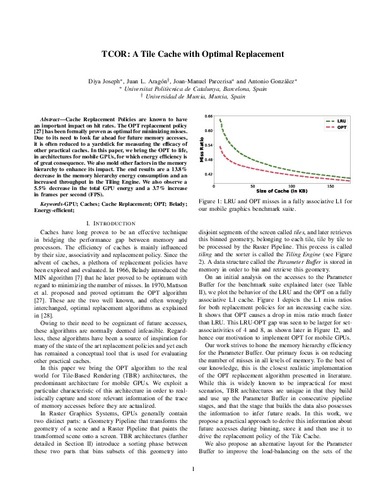
TCOR: a tile cache with optimal replacement
(Institute of Electrical and Electronics Engineers (IEEE), 2022)
Text en actes de congrés
Accés obertCache Replacement Policies are known to have an important impact on hit rates. The OPT replacement policy [27] has been formally proven as optimal for minimizing misses. Due to its need to look far ahead for future memory ... -
Improving the energy efficiency of the graphics pipeline by reducing overshading
(2021)
Text en actes de congrés
Accés obertThe most common task of GPUs is to render images in real time. When rendering a 3D scene, a key step is determining which parts of every object are visible in the final image. There are different approaches to solve the ... -
A low-power hardware accelerator for ORB feature extraction in self-driving cars
(Institute of Electrical and Electronics Engineers (IEEE), 2021)
Text en actes de congrés
Accés obertSimultaneous Localization And Mapping (SLAM) is a key component for autonomous navigation. SLAM consists of building and creating a map of an unknown environment while keeping track of the exploring agent's location within ... -
Boosting LSTM performance through dynamic precision selection
(Institute of Electrical and Electronics Engineers (IEEE), 2020)
Text en actes de congrés
Accés obertThe use of low numerical precision is a fundamental optimization included in modern accelerators for Deep Neural Networks (DNNs). The number of bits of the numerical representation is set to the minimum precision that is ... -
Demystifying power and performance bottlenecks in autonomous driving systems
(Institute of Electrical and Electronics Engineers (IEEE), 2020)
Text en actes de congrés
Accés obertAutonomous Vehicles (AVs) have the potential to radically change the automotive industry. However, computing solutions for AVs have to meet severe performance and power constraints to guarantee a safe driving experience. ... -
DRAM errors in the field: a statistical approach
(Association for Computing Machinery (ACM), 2019)
Text en actes de congrés
Accés obertThis paper summarizes our two-year study of corrected and uncor-rected errors on the MareNostrum 3 supercomputer, covering 2000 billion MB-hours of DRAM in the field. The study analyzes 4.5 million corrected and 71 uncorrected ... -
Neuron-level fuzzy memoization in RNNs
(Association for Computing Machinery (ACM), 2019)
Text en actes de congrés
Accés obertRecurrent Neural Networks (RNNs) are a key technology for applications such as automatic speech recognition or machine translation. Unlike conventional feed-forward DNNs, RNNs remember past information to improve the ... -
Leveraging run-time feedback for efficient ASR acceleration
(Institute of Electrical and Electronics Engineers (IEEE), 2019)
Text en actes de congrés
Accés obertIn this work, we propose Locality-AWare-Scheme (LAWS) for an Automatic Speech Recognition (ASR) accelerator in order to significantly reduce its energy consumption and memory requirements, by leveraging the locality among ... -
SCU: a GPU stream compaction unit for graph processing

(Association for Computing Machinery (ACM), 2019)
(Association for Computing Machinery (ACM), 2019)
Text en actes de congrés
Accés restringit per política de l'editorialGraph processing algorithms are key in many emerging applications in areas such as machine learning and data analytics. Although the processing of large scale graphs exhibits a high degree of parallelism, the memory access ...